
Разрешение неоднозначности гласных верхнего подъёма (⟨ï⟩ / ⟨i⟩ / ⟨ı⟩) в OCR-оцифрованных изданиях древнетюркских текстов: слой дизамбигуации, основанный на метаданных издания
Просмотры: 74 / Загрузок PDF: 28
DOI:
https://doi.org/10.32523/2664-5157-2026-2SI-229-241Ключевые слова:
древнетюркский язык, OCR (оптическое распознавание текста), нормализация текста, TEI-P5, гласные верхнего подъёма, графемная неоднозначность, цифровая филология, исторические корпусы, тюркология, дизамбигуацияАннотация
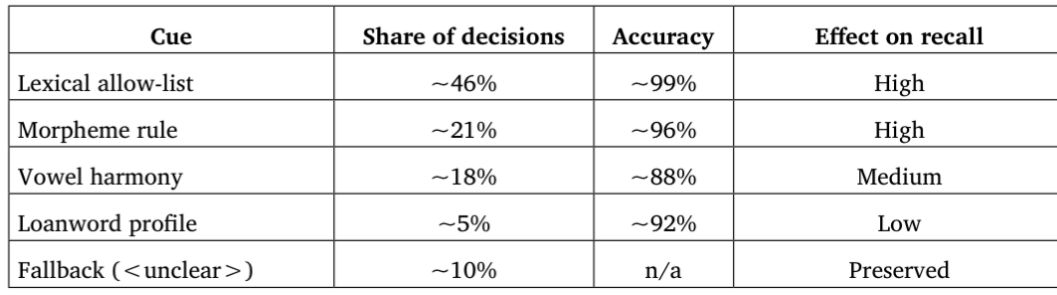
Данное исследование рассматривает проблему неоднозначности гласных верхнего подъёма в OCR-оцифрованных древнетюркских текстах, в которых графемное различие между ⟨ï⟩, ⟨i⟩ и ⟨ı⟩ часто нейтрализуется до ⟨i⟩. Эта проблема обусловлена ограничениями существующих методов нормализации, которые недостаточно учитывают орфографические особенности отдельных изданий и вариативность редакционных традиций. В результате значительная часть исходной графемной информации утрачивается в процессе цифровизации, что снижает надёжность последующего лингвистического и филологического анализа. Для решения данной проблемы в работе предлагается специализированный слой дизамбигуации, интегрированный в двухуровневую систему кодирования TEI-P5 (orig/reg). Данный слой функционирует строго на уровне представления и не предполагает восстановления фонологии или изменения исходного OCR-вывода. Вместо этого он сочетает метаданные конкретных изданий с лингвистически обусловленными правилами, включая лексические списки разрешённых форм, морфологические ограничения, модели гармонии гласных и профили заимствованных слов. Модель использует детерминированную систему приоритетов, обеспечивая прозрачное, последовательное и воспроизводимое разрешение каждой неоднозначности. По своей конструкции она исключает вероятностные методы и отдаёт приоритет филологической проверяемости над статистическим обобщением. Модель была протестирована на корпусе из 4485 токенов, извлечённых из тринадцати изданий древнетюркских текстов, опубликованных в период с 1919 по 2023 год. Из них 1837 токенов сохраняли неоднозначность гласных верхнего подъёма после нормализации. Предложенный метод успешно разрешает приблизительно 88–93% таких случаев в зависимости от издания, при этом неразрешённые формы сохраняются посредством явной TEI-аннотации <unclear>. Такой подход не скрывает неоднозначность, а сохраняет её в явном виде, обеспечивая доступность для последующего филологического анализа и интерпретации. Сравнительный анализ различных изданий подтвердил устойчивость метода при различных орфографических традициях. Результаты показывают, что детерминированный, ориентированный на особенности издания подход может существенно повысить точность по сравнению с базовыми методами, не снижая при этом прозрачности, обратимости и интерпретируемости. Исследование также подчёркивает важность редакционных традиций в формировании графемной репрезентации и демонстрирует, что неоднозначность может эффективно управляться с помощью структурированных метаданных и ограниченных систем правил. Предложенный фреймворк представляет собой воспроизводимое и расширяемое решение для повышения качества, согласованности и интероперабельности OCR-оцифрованных исторических корпусов в тюркологии и цифровой филологии. Дальнейшие исследования будут направлены на расширение фреймворка на дополнительные тюркские издания и его интеграцию с инструментами корпусного поиска, и аннотирования.
Скачивания
Литература
Arat R.R., 1965. Eski Türk Şiiri [Old Turkic Poetry]. Ankara: Türk Tarih Kurumu Yayınları [Ankara: Turkish Historical Society Publications]. [in Turkish].
Bang W., 1923. Manichaeische Laien-Beichtspiegel [Manichaean Lay Confessional Mirror]. Le Muséon. 36. P. 137–242. [in German].
Carlson J. et al., 2023. Efficient OCR for building a diverse digital history. arXiv preprint arXiv:2304.02737.
Clauson G., 1972. An Etymological Dictionary of Pre-Thirteenth Century Turkish. Oxford: Clarendon Press.
Dietz S. et al., 2015. Die alttürkische Xuanzang-Biographie V: Nach der Handschrift von Leningrad, Paris und Peking sowie nach dem Transkript von Annemarie v. Gabain (Hrsg., Übers., Komm.) [The Old Turkic Xuanzang Biography V: Based on the Manuscripts from Leningrad, Paris and Beijing and the Transcript by Annemarie von Gabain (ed., trans., comm.)]. Wiesbaden: Harrassowitz Verlag. [in German].
Erdal M., Gippert J., Röhrborn K., Zieme P., Nevskaya I., Knüppel M., Özertural Z., Taube J., 2003. Vorislamische Alttürkische Texte: Elektronisches Corpus. [Electronic resource]. Available at: https://vatec2.fkidg1.uni-frankfurt.de
Geng S., 1989. A study of one newly discovered folio of the Uighur Abhidharmakośaśāstra. Central Asiatic Journal. 33. P. 36–45.
Hamilton J.R., 1971. Le conte bouddhique du bon et du mauvais prince en version ouïgoure [The Buddhist Tale of the Good and the Bad Prince in Uighur Version]. Paris: Klincksieck. [in French].
Kaya C., 2023. Uygurca Altun Yaruk: Belgeler. Ankara: Türk Dil Kurumu Yayınları [Uighur Altun Yaruk: Documents. Ankara: Turkish Language Association Publications]. [in Turkish].
Le Coq A. von., 1919. Kurze Einführung in die uigurische Schriftkunde [A Short Introduction to Uighur Paleography]. Mitteilungen des Seminars für Orientalische Sprachen an der Friedrich-Wilhelms-Universität zu Berlin [Proceedings of the Seminar for Oriental Languages at the Friedrich Wilhelm University of Berlin, West Asian Studies]. Westasiatische Studien. 22. P. 93–109. [in German].
Özateş Ş. et al., 2025. Building foundations for natural language processing of historical Turkish: Resources and models. arXiv preprint arXiv:2501.04828. (Accessed: 20.04.26)
Röhrborn K., 1971. Eine uigurische Totenmesse: Text, Übersetzung, Kommentar [A Uighur Funeral Mass: Text, Translation]. Berliner Turfantexte 1. Berlin: Akademie Verlag. [in German].
TEI Consortium, 2024. TEI P5: Guidelines for Electronic Text Encoding and Interchange (Version 4.7.0, tei-c.org). (Accessed: 20.04.26)
Uçar E., 2020. Türkiye’deki Eski Uygurca Metin Neşirleri İçin Kullanılacak Harfçevrim ve Yazıçevrim Kılavuzu [Grapheme and Transliteration Guide for Old Uighur Text Editions in Turkey]. Journal of Old Turkic Studies. 4(1). P. 231–250. [in Turkish].
Uçar E., 2021. Türkiye’deki Manihey Harfli Eski Uygurca Neşirler İçin Harfçevrim ve Yazıçevrim Kılavuzu [Grapheme and Transliteration Guide for Manichaean Script Old Uighur Editions in Turkey]. Journal of Old Turkic Studies. 5(1). P. 161–194. [in Turkish].
Uçar E., 2026. A Normalization Layer for Old Turkic Text Editions in OCR-Based Workflows. (forthcoming).
Zieme P. et al., 2022. Avalokiteśvara-Sūtras: Edition altuigurischer Übersetzungen nach Fragmenten aus Turfan und Dunhuang [Avalokiteśvara Sutras: Edition of Old Uighur Translations Based on Fragments from Turfan and Dunhuang]. Berliner Turfantexte 50. Turnhout: Brepols. [in German].
Загрузки
Опубликован
Как цитировать
Выпуск
Раздел
Лицензия
Copyright (c) 2026 Э. Учар

Это произведение доступно по лицензии Creative Commons «Attribution-NonCommercial» («Атрибуция — Некоммерческое использование») 4.0 Всемирная.






















