
OCR арқылы цифрланған көне түркі мәтіндері басылымдарындағы қысаң дауыстылардың (⟨ï⟩ / ⟨i⟩ / ⟨ı⟩) көпмәнділігін басылым метадеректеріне сүйене отырып ажырату: дизамбигуация қабаты
Қаралымдар: 74 / PDF жүктеулері: 28
DOI:
https://doi.org/10.32523/2664-5157-2026-2SI-229-241Кілт сөздер:
көне түркі тілі, OCR (оптикалық мәтінді тану), мәтінді нормализациялау, TEI-P5, қысаң дауыстылар, графемалық көпмәнділік, цифрлық филология, тарихи корпустар, түркология, дизамбигуацияАннотация
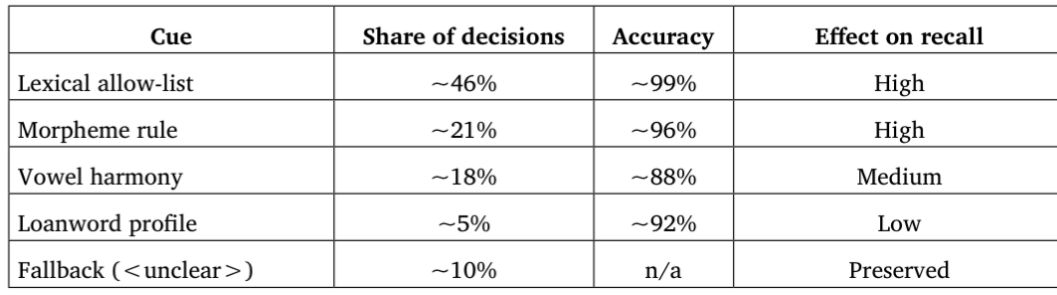
Бұл зерттеу OCR арқылы цифрланған көне түркі мәтіндеріндегі қысаң дауыстылардың көпмәнділігі мәселесін қарастырады, мұнда ⟨ï⟩, ⟨i⟩ және ⟨ı⟩ арасындағы графемалық айырмашылық көбінесе ⟨i⟩ түріне дейін бейтараптанады. Бұл мәселе қолданыстағы нормализация әдістерінің шектеулерінен туындайды, олар жекелеген басылымдардың орфографиялық ерекшеліктерін және редакциялық дәстүрлердің вариативтілігін жеткілікті түрде ескермейді. Соның салдарынан цифрландыру барысында бастапқы графемалық ақпараттың елеулі бөлігі жоғалып, кейінгі лингвистикалық және филологиялық талдауларға әсер етіп, шынайылығын төмендетеді. Бұл мәселені шешу үшін зерттеу жұмысымызда TEI-P5 екі деңгейлі кодтау жүйесіне (orig/reg) интеграцияланған арнайы дизамбигуация қабаты қоса ұсынылады. Ұсынылған қабат қатаң түрде тек репрезентация деңгейінде ғана жұмыс істейді және фонологияны қайта қалпына келтіруге немесе OCR нәтижесін өзгертуге келмейді. Оның орнына ол нақты басылымдардың метадеректерін лингвистикалық белгілерге негізделген ережелермен біріктіреді, соның ішінде рұқсат етілген лексикалық тізімдер, морфологиялық шектеулер, дауысты дыбыстар үндестігінің үлгілері және кірме сөздер профилін де қоса алады. Модель қатаң белгіленген ережелер жүйесіне басымдық береді, әрбір көпмәнді жағдайдың ашық, бірізді және қайталанатын түрде шешілуін қамтамасыз етеді. Құрылымы бойынша модель ықтималдық әдістерін қолданбайды және статистикалық жалпылаудан гөрі филологиялық есеп берушілікке басымдық береді. Модель 1919–2023 жылдар аралығында жарияланған көне түркі мәтіндерінің он үш басылымынан алынған 4485 токеннен тұратын деректер жиынында бағаланды. Олардың ішінде 1837 токен нормализациядан кейін қысаң дауыстылар бойынша көпмәнділікті сақтаған. Ұсынылған әдіс басылымға байланысты осы жағдайлардың шамамен 88–93%-ын сәтті ажыратады, ал шешілмеген формалар TEI (unclear) аннотациясы арқылы сақталады. Бұл тәсіл көпмәнділікті жасырмай, оны айқын күйде қалдырып, кейінгі филологиялық талдау мен интерпретация үшін қолжетімді етеді. Басылымдар арасындағы салыстырмалы талдау әдістің әртүрлі орфографиялық дәстүрлер жағдайында тұрақтылығын растады. Нәтижелер қатаң белгіленген және басылым ерекшеліктерін ескеретін тәсілге негізделген базалық әдістермен салыстырғанда дәлдікті едәуір арттыра алатынын, сонымен бірге ашықтықты, кері қайтарылымдылықты және интерпретацияланушылықты сақтайтынын көрсетеді. Зерттеу сондай-ақ редакциялық дәстүрлердің графемалық репрезентацияны қалыптастырудағы маңызын атап өтеді және көпмәнділікті құрылымдалған метадеректер мен шектелген ережелер жүйесі арқылы тиімді басқаруға болатынын көрсетеді. Ұсынылған фреймворк түркология мен цифрлық филологияда OCR арқылы цифрланған тарихи корпустардың сапасын, бірізділігін және интероперабельділігін арттыруға арналған қайта жаңғыртылатын және кеңейтілетін шешім ұсынады. Болашақ жұмыс фреймворкты қосымша түркі басылымдарына кеңейтуге және оны корпус деңгейіндегі іздеу мен аннотация құралдарымен біріктіруге бағытталады.
Downloads
Әдебиет
Arat R.R., 1965. Eski Türk Şiiri [Old Turkic Poetry]. Ankara: Türk Tarih Kurumu Yayınları [Ankara: Turkish Historical Society Publications]. [in Turkish].
Bang W., 1923. Manichaeische Laien-Beichtspiegel [Manichaean Lay Confessional Mirror]. Le Muséon. 36. P. 137–242. [in German].
Carlson J. et al., 2023. Efficient OCR for building a diverse digital history. arXiv preprint arXiv:2304.02737.
Clauson G., 1972. An Etymological Dictionary of Pre-Thirteenth Century Turkish. Oxford: Clarendon Press.
Dietz S. et al., 2015. Die alttürkische Xuanzang-Biographie V: Nach der Handschrift von Leningrad, Paris und Peking sowie nach dem Transkript von Annemarie v. Gabain (Hrsg., Übers., Komm.) [The Old Turkic Xuanzang Biography V: Based on the Manuscripts from Leningrad, Paris and Beijing and the Transcript by Annemarie von Gabain (ed., trans., comm.)]. Wiesbaden: Harrassowitz Verlag. [in German].
Erdal M., Gippert J., Röhrborn K., Zieme P., Nevskaya I., Knüppel M., Özertural Z., Taube J., 2003. Vorislamische Alttürkische Texte: Elektronisches Corpus. [Electronic resource]. Available at: https://vatec2.fkidg1.uni-frankfurt.de
Geng S., 1989. A study of one newly discovered folio of the Uighur Abhidharmakośaśāstra. Central Asiatic Journal. 33. P. 36–45.
Hamilton J.R., 1971. Le conte bouddhique du bon et du mauvais prince en version ouïgoure [The Buddhist Tale of the Good and the Bad Prince in Uighur Version]. Paris: Klincksieck. [in French].
Kaya C., 2023. Uygurca Altun Yaruk: Belgeler. Ankara: Türk Dil Kurumu Yayınları [Uighur Altun Yaruk: Documents. Ankara: Turkish Language Association Publications]. [in Turkish].
Le Coq A. von., 1919. Kurze Einführung in die uigurische Schriftkunde [A Short Introduction to Uighur Paleography]. Mitteilungen des Seminars für Orientalische Sprachen an der Friedrich-Wilhelms-Universität zu Berlin [Proceedings of the Seminar for Oriental Languages at the Friedrich Wilhelm University of Berlin, West Asian Studies]. Westasiatische Studien. 22. P. 93–109. [in German].
Özateş Ş. et al., 2025. Building foundations for natural language processing of historical Turkish: Resources and models. arXiv preprint arXiv:2501.04828. (Accessed: 20.04.26)
Röhrborn K., 1971. Eine uigurische Totenmesse: Text, Übersetzung, Kommentar [A Uighur Funeral Mass: Text, Translation]. Berliner Turfantexte 1. Berlin: Akademie Verlag. [in German].
TEI Consortium, 2024. TEI P5: Guidelines for Electronic Text Encoding and Interchange (Version 4.7.0, tei-c.org). (Accessed: 20.04.26)
Uçar E., 2020. Türkiye’deki Eski Uygurca Metin Neşirleri İçin Kullanılacak Harfçevrim ve Yazıçevrim Kılavuzu [Grapheme and Transliteration Guide for Old Uighur Text Editions in Turkey]. Journal of Old Turkic Studies. 4(1). P. 231–250. [in Turkish].
Uçar E., 2021. Türkiye’deki Manihey Harfli Eski Uygurca Neşirler İçin Harfçevrim ve Yazıçevrim Kılavuzu [Grapheme and Transliteration Guide for Manichaean Script Old Uighur Editions in Turkey]. Journal of Old Turkic Studies. 5(1). P. 161–194. [in Turkish].
Uçar E., 2026. A Normalization Layer for Old Turkic Text Editions in OCR-Based Workflows. (forthcoming).
Zieme P. et al., 2022. Avalokiteśvara-Sūtras: Edition altuigurischer Übersetzungen nach Fragmenten aus Turfan und Dunhuang [Avalokiteśvara Sutras: Edition of Old Uighur Translations Based on Fragments from Turfan and Dunhuang]. Berliner Turfantexte 50. Turnhout: Brepols. [in German].
Жүктеулер
Жарияланды
Дәйексөзді қалай келтіруге болады
Журналдың саны
Бөлім
Лицензия
Авторлық құқық (c) 2026 Э. Учар

Бұл жұмыс Creative Commons Attribution-Коммерциялық емес 4.0 халықаралық лицензиясы.






















